正则表达式作为一种方便的符号匹配规则,实现时必须依赖一套高效的算法,这套算法就被称之为正则表达式引擎。实现正则表达式引擎的方法分为两种:DFA自动机(Deterministic Final Automata | 确定型有穷自动机)和NFA自动机(Nondeterministic Final Auomaton | 不确定型有穷自动机)。
原理简析
DFA
在输入一个状态时,只得到一个固定的状态。DFA有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA中不会有从同一状态出发的两条边标志有相同的符号。
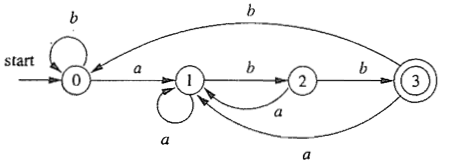
简单来说,对于正则匹配,就是待匹配的字符逐个读入,每读入一个字符,即判断它可能的后续匹配情况,进而继续读取下一个字符,在每种可能的基础上继续匹配,抛弃匹配失败的情况,如此进行下去,直至匹配完成。
举例
1 | /abc{1, 3}d*[db]/g.test('abccdb') |
- 读入字符串中的字符
a与表达式中的a匹配,匹配成功,经判断发现只有向后继续匹配一种可能,移动匹配位置到b; - 继续读入字符
b,同上,移动匹配位置到c,发现c可能出现3中匹配情况(1-3个c),于是产生三条匹配路径; - 继续读入字符
c,3种情况都匹配成功,匹配1个c的情况移动匹配位置至d,发现两种新的可能(匹配d*的d或者匹配[db]中的d); - 继续读入第二个字符
c,只出现一个c的情况匹配失败,只剩下(2-3个c两种情况),第2种情况同样移动匹配位至d并发现两种新的匹配可能; - 继续读入字符
d,出现3个c的情况匹配失败,d继续与2个c情况下的d*和[db]分别匹配,均匹配成功,均向后移动匹配位,d*后又发展出现两种情况(d*or[db]); - 继续读入字符
b,发现d*下的另外两种可能都失败,只剩下[db]这样的情况匹配成功; - 返回true。
NFA
对每个状态和输入符号都可以有多个可能的下一个状态(甚至是空)。因此,在形式化定义中,下一个状态是状态的幂集的元素,这是一组要立即考虑的状态。
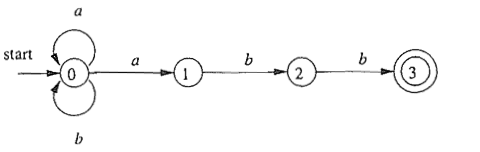
简单来说,对于正则匹配,同样逐个读入待匹配字符,每读一个字符,即选取多种可能的匹配规则的一种继续匹配,一旦发现匹配失败,则回溯(backtrack)到之前的状态,重新开始尝试新的一种匹配,直至匹配完成。
举例
1 | /abc{1, 3}?d*[db]/g.test('abccdb') |
- 读入字符串中的
a与正则中的a匹配,匹配成功,匹配位移动至b; - 读入字符串中的
b,同上; - 读入字符串中的
c,匹配成功,由于是lazy模式(因为可回溯,所以是NFA特有的功能),移动匹配位置到d; - 继续读入字符串中的第二个
c,匹配失败,匹配位回溯到上一位,发现匹配位中的c只匹配过一次,则与该位置匹配,匹配成功后继续移动匹配位到d; - 继续读入字符串中的
d,匹配成功,由于可能存在多匹配的情况,保持匹配位; - 继续读入字符
b,匹配失败,移动匹配位至下一位,匹配失败; - 回溯匹配至字符串中
d匹配之前,将d与[db]中的d匹配,匹配成功; - 将
b与[db]中的b匹配,匹配成功; - 返回true。
区别
DFA
DFA自动机的时间复杂度是线性的,比起NFA自动机来说,更加稳定,但其功能受限(不记录所有可能的路径)。DFA匹配速度,基于文本(扫描),结果是确定的。
NFA
NFA自动机的时间复杂度较不稳定,好坏程度取决于正则表达式的书写与匹配对象的复杂程度(Backtrak <回溯>)。但NFA相较于DFA,它具有更强大的功能。因此,它也成为Java,JavaScript,PHP,Python,Ruby实现正则表达式的方式。NFA匹配结果,基于表达式,它记录所有可能的路径。